Optimized server-less data architecture in AWS
Business case for Electrical sector in Spain 2021
Simig Solutions
has created a scalable plug and play cloud solution using AWS best practices in
Data Pipeline management to store and analyze data in a performant and
cost-efficient manner.
Besides this
document focuses on a specific business case, best practices mentioned here can
be applicable to other industries aiming to streamline their data management systems.
1. Business Goal
Regulation in the Power and Energy sector is always a key element of this industry. In June 2021, Spanish regulation has changed, and it became crucial than ever keeping a close monitoring of consumption and commercial margins.
The business goals of this solution are to allow
companies to process, maintain and secure their data to analyze, understand and
improve:
- Customer profitability
- Consumption forecast
- Fraud detection
That will lead into an optimize pricing
strategy and betting and more accurate predictions of energy needed.
On this document will be described the set
up to achieve our 1st objective à Customer
profitability analysis
2. The Challenge
Power marketer companies are usually supplied with electricity from multiple sources to ensure grid reliability. REE (Red Eléctrica España) defines how that consumption needs to be saved in a standardized formats allowing information sharing between different stakeholders.
The electric load of their customers, measured in watts (W) or KW, is dynamically fluctuating and it is saved in an hourly base assigning that consumption to the Universal Supply Point Code (acronym CUPS in Spanish).
“Currently electrical consumption is saved hourly, but it will be up to 15 min in a near future”
Each CUPS has an electricity sensor that takes all the consumption and inserts them into one or more data storage. Furthermore, most of these companies have their metering, SCADA and customer data, locked away in separate incompatible data silos.
Usually, the large amount of data from consumption
and the master data of the company cannot be analyzed in a simple and reliable manner
to deploy from simple dashboards to predicting demand at substation or
distribution level.
Alternatives such as using manual spreadsheets
for reporting and visualizing the data do not allow coworkers to collaborate
interactively and perform analytics in a more centralized way; and sometimes
granting full unrestricted access to the datasets and dashboards.
3. Solution Architecture
Here it will be shown the approach
following in our packed solution to effortlessly automate the data extraction,
transformation, and building of an accurate data lake with specific cloud
native AWS services to meet the needs of the electric power industry.
It has minimized operational overhead and allowed the filing of business reports and KPIs while ensuring that the data being consumed for analytics, AI/ML, and reporting is always accurate and up to date.

3.1 - AWS Transfer Family
Even though energy companies have globally already adopted the SFTP protocol for file transfers, many of them apply methods that lack a viable server-less solution for a secure file transfer that can integrate with the existing cloud infrastructure and achieve segregation between tenants.This is where the AWS Transfer Family helps us achieve all file transfer requirements. It is also highly reliable, highly resilient, and can successfully meet our file transfer SLAs rapidly and in a cost-effective way across various AWS environments as well as on the premises.
Main benefits:
- Server-less solution
- Cost effective
- Cloud native integration
3.2 – S3 buckets
S3 is a cloud storage service, that is highly durable, and scalable, low cost, and that integrates with all the AWS’s services in our solution. It has a main role on the ETL pipeline allowing fast performance on:
- Moving, reading, and securing the data
- As well as on storing and archiving the processed data.
Main benefits:
- Cost effective solution
- High performance
- High availability thanks to data replication
3.3 – AWS Lambda
AWS Lambda is an event-driven serverless computing platform, which help us trigger the ETL job in response to specific user’s actions, such as new data available.Lambda has a pay-as-you-go pricing model with a generous free tier, and its billing is based on used memory, the number of requests and execution duration, which translates into an 85% average cost reduction against on-premises alternatives.
Main benefits:
- Trigger ETL job event based
- Free tier (enough for most implementations)
3.4 – AWS Glue
The service that fits best for moving and processing complex data between layers in our solution is AWS Glue. AWS Glue is a fully managed serverless Extract, Transform, and Load (ETL) service.Glue strives to address both data setup and processing using:
- The speed and power of Apache Spark
- The lightweight data organization of the Hive metastores, with a minimal infrastructure setup.
Main benefits:
- No upfront cost
- Pay by the time you need. Serverless solution
- Scalable and flexible solution
3.5 – AWS Redshift
Deciding which data warehousing solution to implement is a key evaluation where main points to consider are:
- Scalability and performance
- Integration with data pipeline (how we collect the data)
- Price tag involved
Amazon Redshift has significant benefits based on its massively scalable and fully managed computing underneath to process structured and semi-structured data directly from our consumption and archiving layer in S3 in Apache Parquet, an efficient open columnar storage format for analytics. Parquet format files are up to two times faster to unload and consume up to six times less storage in S3, compared to text formats.
Amazon Redshift prices are calculated based on hours of usage, which helps us
Main benefits:
- Scalable AWS native data warehouse
- Self-managed solution
- Control on performance and optimizations
4. Data pipeline flow
Once we place the data in our AWS environment, specifically in Amazon Simple Storage Service (Amazon S3), thanks to the AWS Transfer Family, we can go ahead and proceed to process it, meaning we need to:
- Categorize data
- Clean data
- Enrich data
To achieve this, we move the data between different data store layers to ensure full traceability and control.

DATA LAYERS:
RAW:
In the first layer we have the raw data in its native format where it is immutable and should not be accessed from end users.1-1 mapping focused on performance and make sure all data is transferred in the most efficient manner.
STAGING:
The second layer is called Staging, where we move the raw data with the same structure to a format (parquet in our solution) that fits best for cleansing and improving performance.Here is where data validation processes and enrichment of data takes place. That is still not accessible for the end-user.
CONSUMPTION:
The last layer is the Consumption. It has the consumable, normalized, and consolidated dataset that the previous layer processed.Here is where the business logic is applied to covert source data into an Analytical model. End-user can access it for analysis purposes.
5. Integration and scalability
The solution is easily adaptable to changes
on the underlying data, since the ETL job has a parametrized input to automatically
infer schemes and partition structure and populate the different layers of the
process.
- Using standard information
sharing protocols to access the raw data
- Scale-out & pay per use solution
- Parametrized input that allows
easily adding multiple data schemas
6. Performance tunning
All the components mentioned above allow us to increase the performance by triggering the jobs in parallel and sequentially by triggering them on a job completion event. This is done in a bulk load processing mode, inserting the ETL results on the different S3 layers and Redshift ensuring optimal use of cluster resources, and the quickest possible throughput.
- Auto parallelization process to
increase performance
- Using finetuned compute Redshift
cluster
- Materialized view in Redshift
for aggregated common queries
- Sort-keys definition for data
access optimization
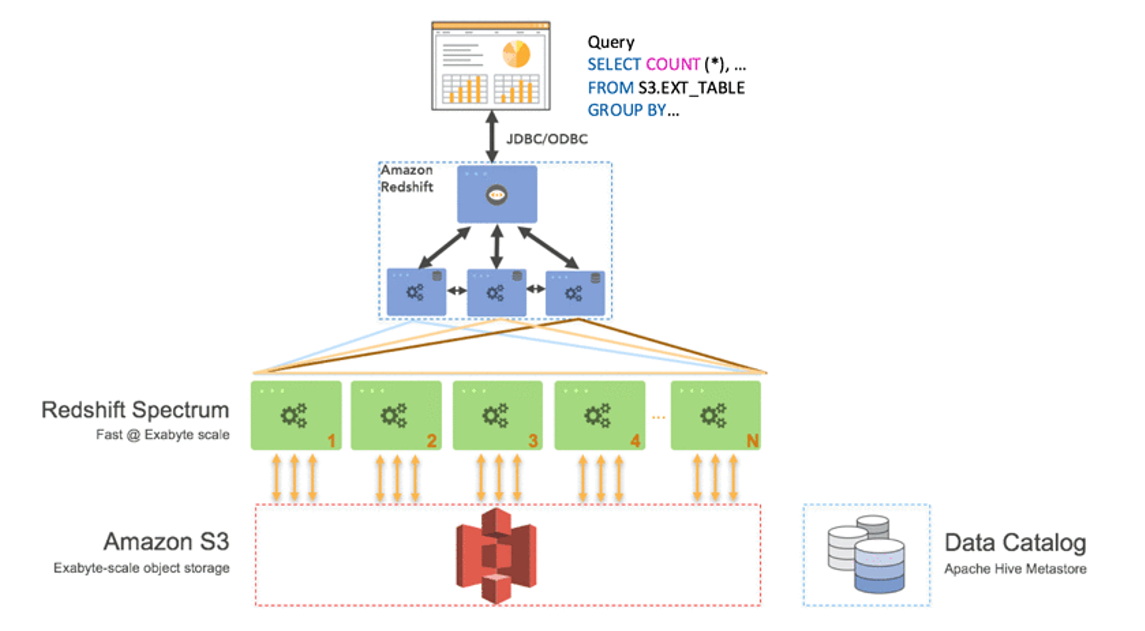
Best practice is storing frequently consumed
data in Redshift for performance optimization but having at the same time all
historical info accessible thought Spectrum (that reads info directly from S3
buckets – consumption layer)
7. Cost Optimization
The suggested architecture allows our
customers to process their data at the lowest price point archiving the highest
saving potential without impacting performance neither scalability.
The identification of straggler tasks in
the jobs, which delay their overall execution, and the configuration of the
ideal number of Glue DPUs for the mentioned jobs, based on the amount of data
our customer needs to process, allows the ETL process to run efficiently,
increasing outputs and reducing costs.
Knowing that, from a data warehouse
perspective, not all the data sitting in it is actively queried. It is reasonable
that any cold data can be kept in S3 storage (Standard-IA) and can be
referenced whenever the need arises. Redshift spectrum provides a way to
reference data sitting in files inside S3 to be directly queried within
Redshift with other hot data stored in Redshift tables. This model can save
more than 50% of costs on Amazon Redshift behaving as a unique data access for front-end
tools.
KEY TAKE AWAY ABOUT COST OPTIMIZATION:
- Storing cold data in Redshift
Spectrum
- Use of server-less services
allowing us to pay only for the minimum time needed
- Parquet file compression reduces
storage while improves data transfer performance
- Reduction on maintenance and
monitoring internal resources
8. Rapid Deployment Solution – AWS Data Pipeline
Our packed solution “RDS – AWS Data Pipeline” by Simig Solutions, can be fully implemented using real customer data in less than two weeks.
“Fully
implemented in less than 2 weeks”
As mentioned before our pipeline starts
with AWS Transfer Family, where we will need to setup the level access policy to
allow the incoming SFTP traffic from your data store.
Some standard clients are the following:
- OpenSSH (a Macintosh
and Linux command line utility)
- WinSCP (a
Windows-only graphical client)
- Cyberduck (a Linux, Macintosh, and Microsoft Windows
graphical client)
- FileZilla (a
Linux, Macintosh, and Windows graphical client)
Once we have the raw data in the new S3
bucket,
- We will catalog it and parameterize
the input of the ETL job
- Our pipeline has standard
controls that could be applied at any datasets to maintain integrity and
governance over the data flow
- You will get a verified, consistent,
and reliable analytics model ready to start analyzing your data
Are you ready to start making use of the
power of data?
Feel free to reach us to know more


Comments
Post a Comment